
Doing Math with Embeddings for Better AI Ad Targeting
Large language models and their adjacent tools are evolving fast and they are a powerful way to improve content classification …
David Fischer
This is an update to our original post on content-based ad targeting. In this post, I'll talk a bit more about our next step, using machine learning (embeddings specifically) to build better contextual ad targeting.
At the end of our last post, we were crawling all our publisher's pages, and categorizing pages into Topics based on page text. We did this by training a model with ~100 examples of each topic, and then storing the topics in our database for fast ad serving.
This gave us a good starting point for targeting ads by topic, but we wanted to get more granular.
This post is written for developers, but if you're interested in how this applies to marketers, check out our marketing-focused post.
Our new approach is to use word embeddings to represent both the advertisers landing page and the publisher pages. This allows us to generate a representation of these pages, which can be compared against each other.
We're currently using Python's SentenceTransformers library to generate these embeddings. We will likely upgrade to a more advanced model in the future, but this was perfect for our initial tests.
A simple example of what this looks like might be:
import requests from bs4 import BeautifulSoup from sentence_transformers import SentenceTransformer # Generate embeddings for a page model = SentenceTransformer(MODEL_NAME, cache_folder=CACHE_FOLDER) text = BeautifulSoup(requests.get(url), 'html.parser').get_text() embedding = model.encode(text) print(embedding.tolist())
We're then using pgvector and pgvector-python to manage these embeddings in Django & Postgres, which is what we're already using in production.
from django.db import models from pgvector.django import VectorField # Store the content in Postgres/Django class Embedding(models.Model): # FK where we keep metadata about the URL analyzed_url = models.ForeignKey( AnalyzedUrl, on_delete=models.CASCADE, related_name="embeddings", ) # Model name so we can use different models in the future model = models.CharField(max_length=255, default=None, null=True, blank=True) # The actual embedding vector = VectorField(dimensions=384, default=None, null=True, blank=True)
Then we're able to query the database for the most similar publisher pages to an advertiser's landing page:
from pgvector.django import CosineDistance from .models import Embedding # Find the most similar ads for the page we're serving an ad on Embedding.objects.annotate( distance=CosineDistance("vector", embedding) ).order_by("distance")
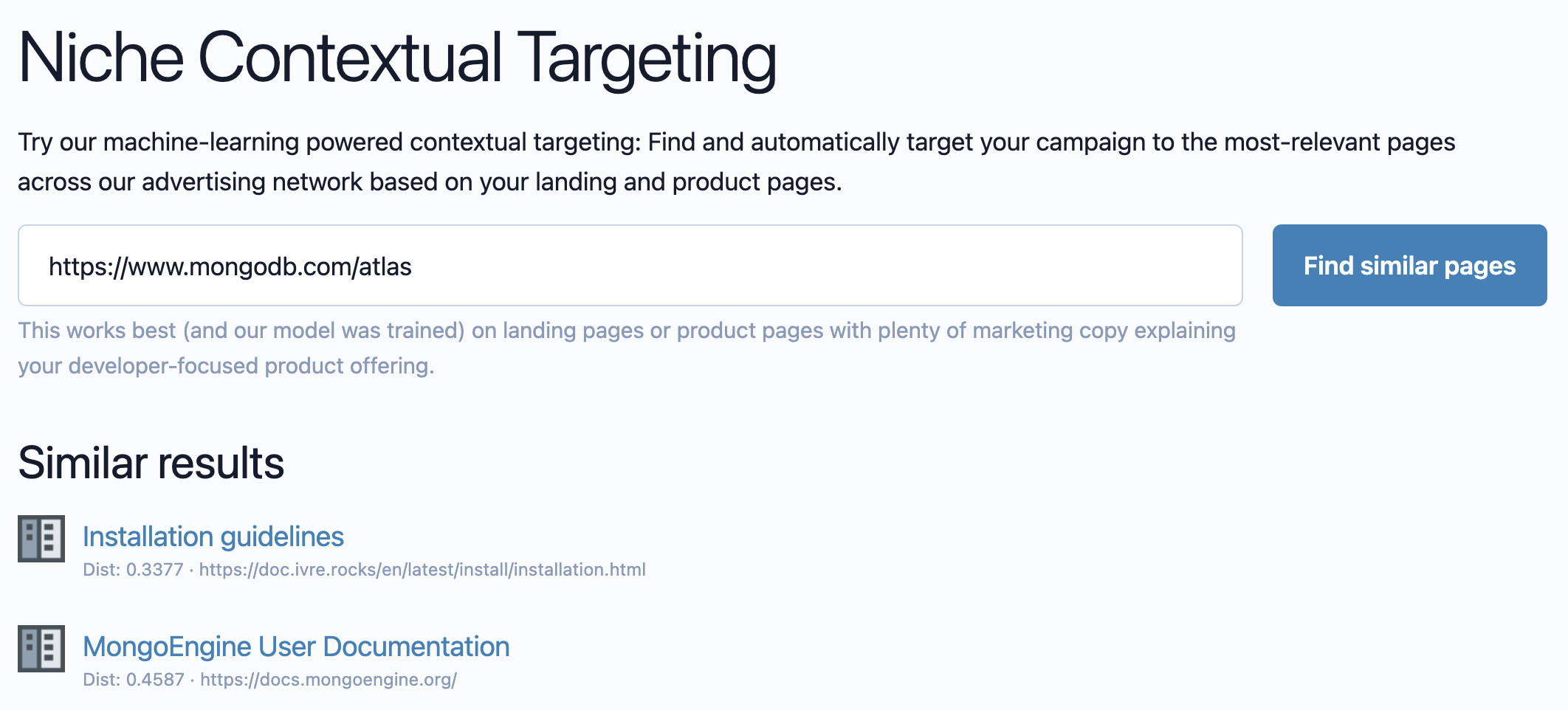
You can see a screenshot of our niche targeting in action at the top of this page. This is a simple proof of concept, but you can see how we're able to target ads specifically focusing on MongoDB and Databases, when serving a MongoDB ad.
You can try out our Niche Targeting Demo, and let us know how it goes!
There is a huge win both in terms of privacy and user experience with this approach:
We have a few challenges to overcome with this approach:
This approach is still in its early stages, but we're excited about the potential. The better we can get at ethical ad targeting, everyone in our network benefits:
This is our vision for advertising, and we're excited about the potential of this approach.
Thanks so much to Simon Willison for his blog post on embeddings, which is what inspired me to try this approach.
Tagged with: content-targeting engineering postgresql
Large language models and their adjacent tools are evolving fast and they are a powerful way to improve content classification …

