
What Happens When Elon Musk Tweets A Link To Your Service
Back in February, one of the publishers on our ad network went truly viral. Simon Willison is the author of …
David Fischer

In a followup post, we discuss a traffic spike to 200 requests per second!
Usually, our blog focuses on advertising, privacy, and our journey in building a business around the intersection of the two. This post is going to go under the hood and discuss some of the technology and scaling challenges we ran into with our ad server.
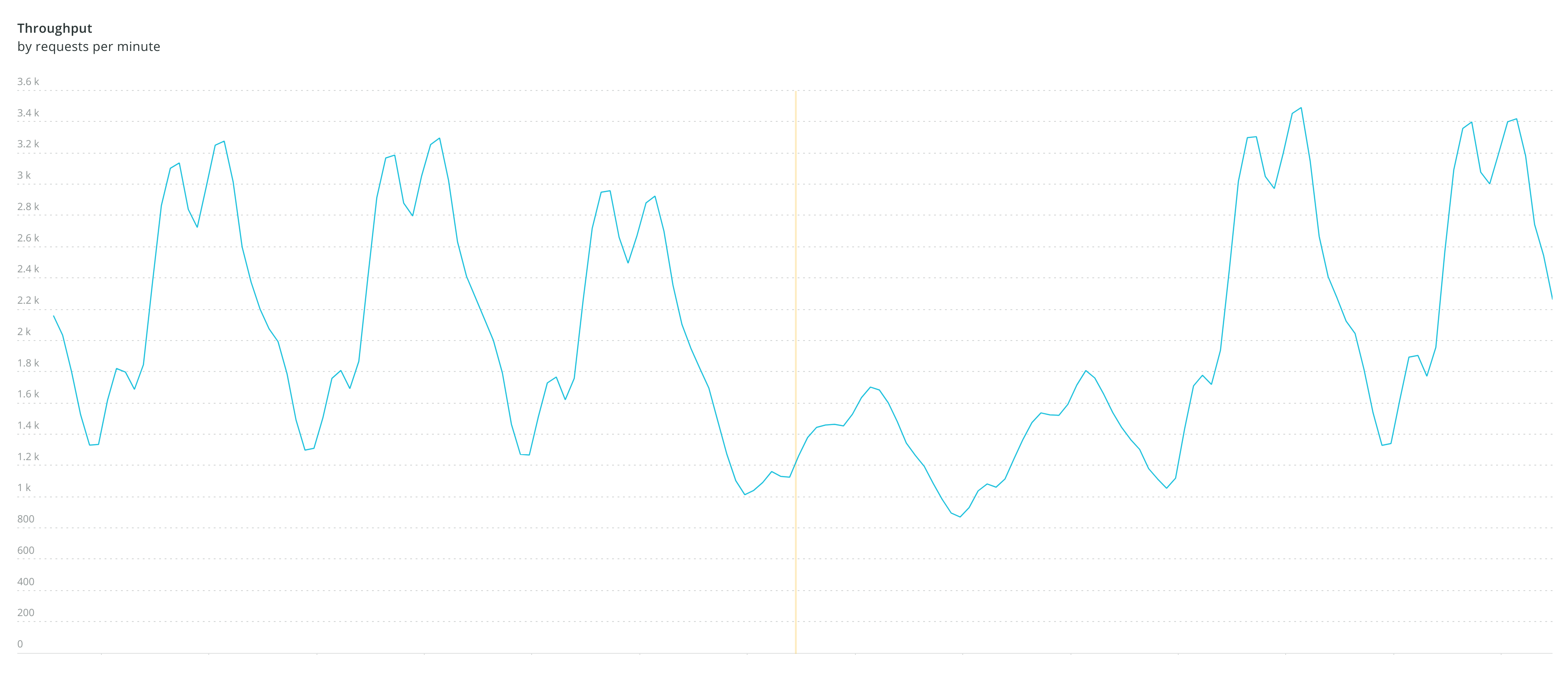
Normal throughput of our ad server peaks at about 3,500 requests per minute which is ~60 requests per second. The small drops are nights and the big ones are weekends.
Before late 2019, ads on Read the Docs were served by a Django app that was actually part of the Read the Docs code line. We knew we wanted to break it out into a separate service to prepare for launching our ad network. However, the process was a bit tricky since we knew that on day one this new server would need to handle around 20-30 requests per second and traffic spikes could take that number to 60 or higher. To prepare for this, we relentlessly focused on our app performance.
Anecdotally, Python and Django are not considered the most performant language and framework. We didn't want to do a from-scratch rewrite, however, in a more performant language. There was also a strong desire to use a similar setup to Read the Docs as that's what our small team (of 5 at that time) knew well.
To improve the performance, we actually spent quite a bit of time digging through New Relic traces and going over each Postgres query in Django Debug Toolbar. For an ad server like ours, just a few different APIs -- like requesting an ad and viewing an ad -- account for almost all transactions. We even have unit tests to ensure the number of database queries doesn't change in these APIs.
When we were pretty confident that the ad server was ready to go live code-wise, we did some load testing to make sure it could handle the traffic. There were definitely a few false starts during the initial rollout and in the end we decided to put it through a full load test.
To make sure we could handle the load we knew we were going to see once we rolled out the ad server, we did a staging deployment to Heroku and to Azure's AppService to compare how they performed. This wasn't particularly complex given that this app was structured to be cloud agnostic from the start. After that, we used siege to test the deployment at various loads up to 100 ad requests per second. These were real requests exactly like we'd see in production and we wanted to see how staging would cope.
This is a pretty standard Heroku setup to handle a performance heavy application. We tested it at various thoughputs but it was able to handle 100 requests per second without dropping requests. However, we did see our 99th percentile performance (p99) creep up to the 550-600ms range which is pretty bad. On Heroku, 100 concurrent requests would also bump us into some pricier Redis and Postgres setups to handle over 100 connections.
In this example, we more than doubled the provisioning. This setup performed much better although it didn't seem to be exactly linearly better which was a little odd. Our p99 was closer to 350ms in a 100 requests per second setup and it didn't drop any requests. The median performance (p50) stayed about the same at 80-90ms.
This was a pretty comparable setup in Azure to the Heroku setups. We ran the exact same code and the configuration was as close as possible. We tested various numbers of instances and the performance scaled very linearly with instance count. Performance was quite a bit better with a p50 of ~75ms and the p99 was drastically improved to ~200ms. Even in longer and larger tests (with more instances in some cases), we saw much better performance on AppService than on Heroku.
The end result of the load tests was that we launched the ad server on AppService where got predictable performance and the right bang for the buck. Heroku definitely wins in ease of deployment and it has a lot of advantages and flexibility. However, for this kind of application where performance and predictability were critical, AppService was the right choice.
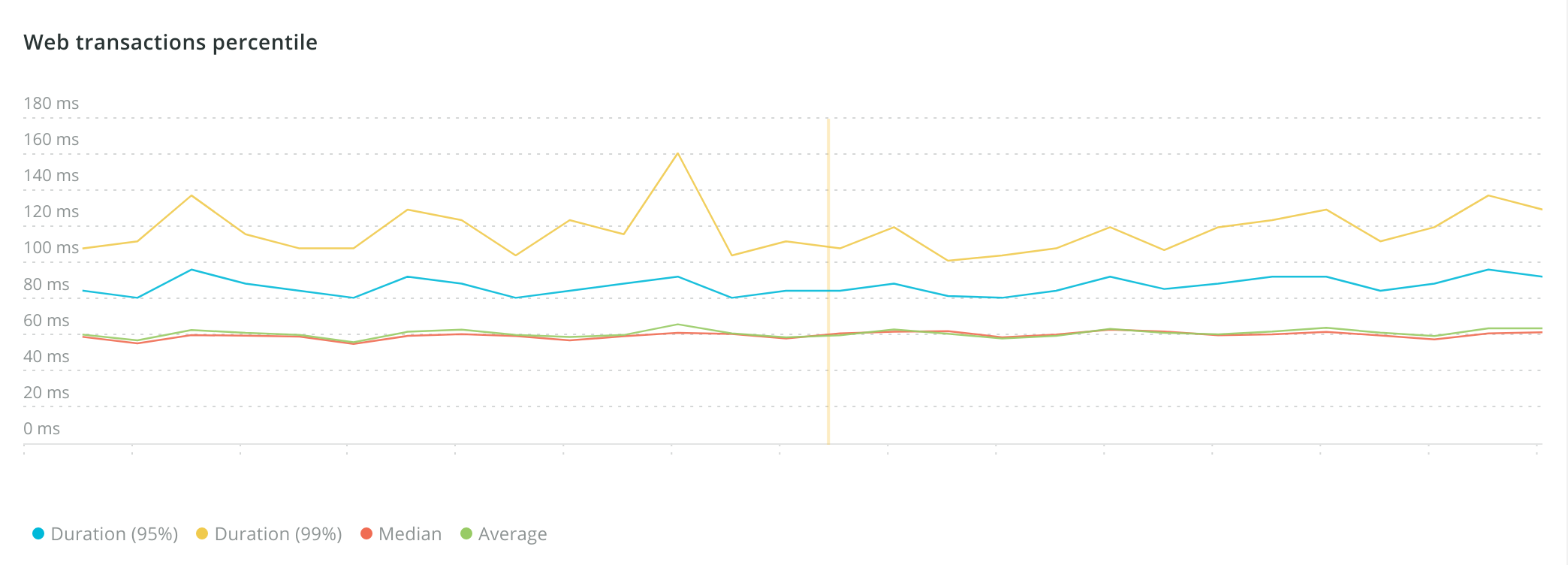
With our current performance over a normal week, New Relic reports our p50 at 58ms and the p99 at 105ms.
A few months after rolling things out to production we encountered some issues with AppService. In response, we switched to autoscaled VM scaling sets. Using the same siege setup, we were able to show that VM scaling sets (which we also use on Read the Docs) not only scaled better but also cut about 15ms off of our p50. We aren't sure why they're faster but we assume it's some overhead with AppService and containerization. That doesn't sound like much but it's actually quite a lot when you consider we didn't change the database or ad server code whatsoever. Except under unusual load, we're usually scaled to about 3-4 instances.
We've done a few further optimizations like reducing cache requests to Redis (the fastest request is the one you don't have to make). Currently, about 20ms of a normal request is taken in Python while the remainder is consumed in Postgres and Redis. This shows the upper bound of any framework or language optimizations. Django and Python may be slow but at most replacing them could shave 10-15ms off our performance. Improvements on our infrastructure or how we handle data would yield better results.
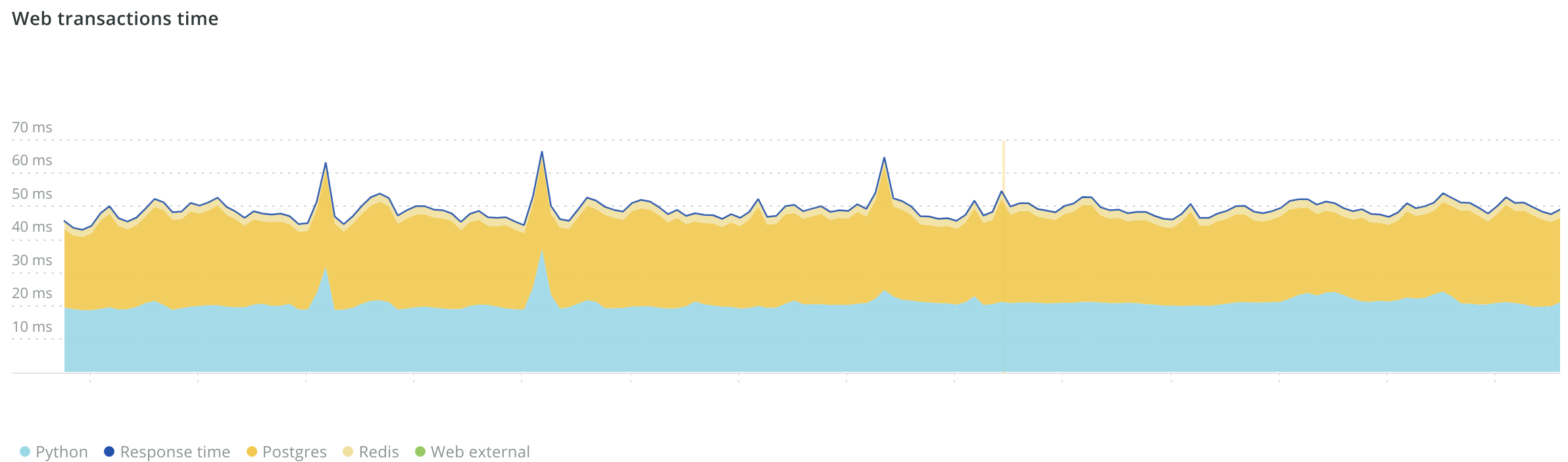
A little over half our server time is spent in Postgres while Python is just under half
Our next big scaling challenge is how to have good performance on different continents. We can optimize server performance all we want but Europe and Asia are 80-100ms worse due purely to latency. Currently, our source of truth is what is in our Postgres database and reworking our solution to actually process ad requests at the edge will be a big change. This will be more complex than CDN edge caching since most of our requests involve DB writes. Multi-writer scenarios for databases are never easy.
Thanks for coming along with us on this journey to build an ethical ad network and the technical challenges that come along with that. Please email us if you have any ideas or feedback on our product or service. We always love to hear from you.